TL;DR. Metadata Manager will be retired at the end of 2025. Over the past four years, we have been developing a new helper tool to replace it, and that tool has now reached a stage of maturity that means we will be able to switch off Metadata Manager by the end of the year.
Our REST API makes all of the metadata we hold publicly available. It receives the majority of our API traffic, with around 1 billion hits per month. It’s one of the key ways that we fulfil our mission to make research objects easy to find, cite, link, assess, and reuse. From 1 December 2025, we will be revising the rate limits for the public and polite pools of the REST API to ensure that we can maintain a stable and reliable system, and that metadata is freely available to everyone.
Noyam Journals, based in Accra, Ghana, was recently recognised for the completeness of its metadata through the Crossref Metadata Award, part of our 25th anniversary celebrations. Noyam was one of six publishers worldwide to receive the award and stood out as a leader among members of our Global Equitable Membership (GEM) Program.
Wednesday 22nd October 2025—Crossref, the open scholarly infrastructure nonprofit, today releases an enhanced dashboard showing metadata coverage and individual organisations’ contributions to documenting the process and outputs of scientific research in the open. The tool helps research-performing, funding, and publishing organisations identify gaps in open research information, and provides supporting evidence for movements like the Barcelona Declaration for Open Research Information, which encourages more substantial commitment to stewarding and enriching the scholarly record through open metadata.
If you are reading this blog on our website, you may have noticed that alongside each post we now list a Crossref DOI link, which was not the case a few months ago (though we have retroactively added DOIs to all older posts too). You can find the persistent link for this post right above this paragraph. Go on, click on it, we’ll wait.
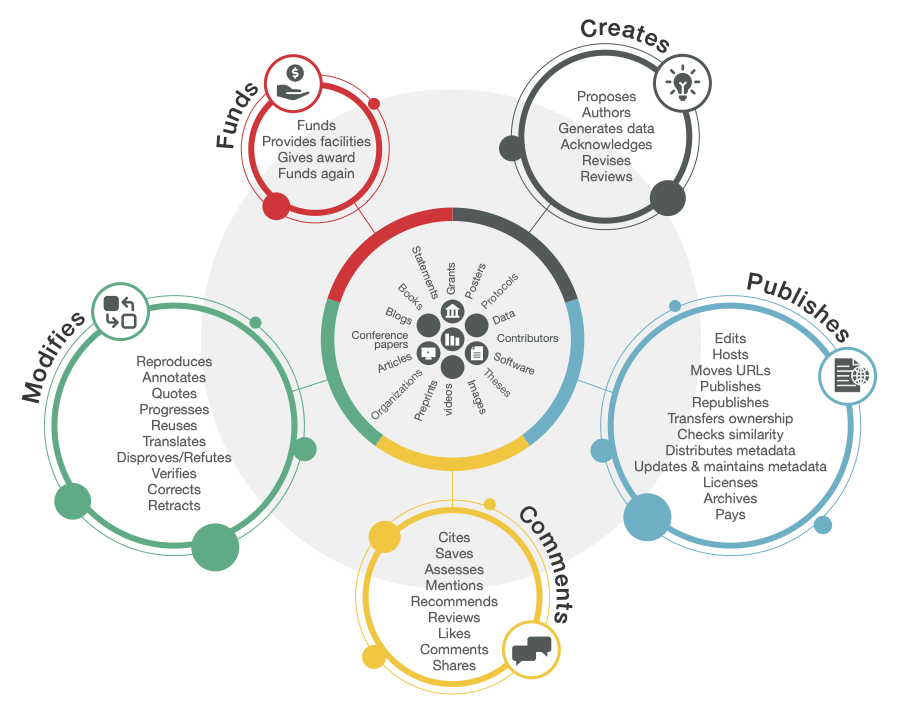
Are you back here? Good. As you probably expected, the DOI link for this post resolves to the post itself, and you should use it anytime you want to cite this post. But the DOI does more than just point readers to this page––it is part of a rich metadata record that includes the authors’ ORCID iDs, the publication date, and more. In other words, the posts on this blog are part of what we call the research nexus: the open network of relationships connecting research outputs, people, organisations, and actions.
Crossref research nexus vision
Why blogs deserve a place in the scholarly record
A blog post may not be the first thing that comes to mind when you think of scholarly outputs. But scholarly blogs have been around since at least the early 2000s and have carved out a niche for themselves as a type of “grey literature” that allows researchers to write about research in a way that may not fit neatly into more traditional, peer-reviewed publishing venues, but also is too long-form for social media. Science blogs can give readers a window into ongoing work that isn’t ready to publish yet, serve as a self-publishing venue, or allow researchers to comment on others’ work and recent developments in science and science communication. These kinds of perspectives add crucial context to the scholarly record that should not be overlooked.
However, as Martin Fenner explained at the #Crossref2023 annual meeting, blogs have largely not benefitted from the metadata and long-term archiving solutions that tend to be applied to more “traditional” forms of publishing. As a result, most blogs have been left out of the scholarly record. But in recent years, there have been some efforts in the community to change this. Earlier this year, ORCID added support for the work type blog post, among others, to align more closely with the Confederation of Open Access Repositories (COAR) vocabulary of resource types.
At our 2025 midyear community update, we asked our community what content types they saw as growing in importance. Blog posts were mentioned several times as a ‘trending’ record type, and as one that members would like to see support for in the Crossref system.
Eating our own dog food
We had already been thinking for a while about how our own blog should be a part of the research nexus. We started out by manually uploading XML files through our Admin tool for each post. We did this for a few months and quickly found, like many of our members do, that this can be a laborious and error-prone process.
In the product management world, the process of using the products you usually spend your time building and maintaining is often referred to as dogfooding. The idea is that firsthand experience makes it easier to understand your end users’ needs and feel their pain - and we have certainly found that registering metadata for our blog posts has reinforced the importance of making manual registration easier for our members, but also of supporting and enabling machine-to-machine integrations.
What did we do?
The Crossref website, which includes this blog, uses an open-source static site generator named Hugo. Rather than using a content management system (CMS), we edit the website content in Markdown format using code editors. Whenever we start working on a post for this blog, we not only write the content of the post itself, but also include some front matter for the page, which contains some key metadata about the post.
We wanted this metadata to be part of the research nexus. But then there was also the question of archiving. Our membership terms state that:
The Member shall use best efforts to contract with a third-party archive or other content host (an “Archive”) (a list of which can be found here) for such Archive to preserve the Member’s Content and, in the event that the Member ceases to host the Member’s Content, to make such Content available for persistent linking.
So we knew that if this blog was to be part of the scholarly record, we would need to ensure that it would be available in perpetuity, even if www.crossref.org were to go offline one day.
Doing this properly was starting to look like a sizeable project!
Fortunately, we knew that others had already done some great work in this field, so we would not have to start from scratch. After considering our options, we opted to integrate our blog with an established workflow for registering blog metadata: the Rogue Scholar service.
The Rogue Scholar was launched in 2023 by Martin Fenner as an archive for scholarly blog posts, hosted by Front Matter. Rogue Scholar improves science blogs in important ways, including full-text search, long-term archiving, and DOIs and metadata, such as versions and relationships along with identifiers such as ORCID iDs and ROR IDs. It provides the necessary tools to treat blog posts as research outputs through better attribution, preservation, and discoverability.
How did we do it?
Rogue Scholar works on the basis of consuming RSS and ATOM feeds (you may remember them from the days of getting headlines direct to your browser or feed reader). We created a new feed, including the proposed DOI as each entry’s id: and taking full advantage of the ATOM format by listing the post’s authors and including their ORCID iDs. We also provide the entire post as the entry’s <content> to allow for full-text indexing and archiving.
For each post, we generate and assign a unique DOI under the Crossref prefix 10.64000. The Rogue Scholar integration then registers the DOI along with the metadata of the post as posted content. If you are interested in getting a similar workflow set up for your blog, you can read more in the Rogue Scholar blog and documentation.
What does the future hold for scholarly blogs?
Researchers are increasingly sharing their early work, or commenting on others’ work, in less formal ways, and if you look at the growth in the number of blogs covered in the Rogue Scholar platform in just a couple of years, it seems like science blogging is here to stay and will only increase. We believe that this practice is an integral part of a healthy scholarly ecosystem, and it needs to be represented in the research nexus.
The Crossref input schema does not include a blog work type, but we are planning to add it as a subtype of posted content in our next schema update. We will discuss this and other plans and ideas in the metadata advisory group that we are currently forming.
If you have thoughts on the role of blogs in the public discourse around science and science communications, or you would like to share your experience of registering metadata for your blog, let us know by commenting below. Your comments will be threaded in our community forum for discussion.